Pairing two protein MSAs by maximising mutual information
DiffPaSS and DiffPaSS-IPA for pairing two interacting MSAs using mutual information.
# Stdlib importsfrom typing import Optional# NumPyimport numpy as np# PyTorchimport torch# Plottingfrom matplotlib import pyplot as plt# Set the number of threads for PyTorchtorch.set_num_threads(8)# DeviceDEVICE = torch.device(f"cuda{(':'+input('Enter the CUDA device number:')) if torch.cuda.device_count() >1else''}"if torch.cuda.is_available() else"cpu")# DEVICE = torch.device("cpu")print(f"Using device: {DEVICE}")# Set the seeds for NumPy and PyTorchNUMPY_SEED =42np.random.seed(NUMPY_SEED)TORCH_SEED =42torch.manual_seed(TORCH_SEED);
Using device: cuda
1. Load the interacting MSAs
We provide two example interacting sequence datasets in FASTA format: HK-RR and MALG-MALK. The HK-RR dataset contains sequences of histidine kinases (HK) and response regulators (RR) from prokaryotic two-component systems. The MALG-MALK dataset contains sequences of the MalG and MalK subunits of the maltose transporter from prokaryotic ABC transporters.
For these datasets, the ground truth pairings are known (using genome proximity). We have ordered the two MSAs in each interacting systems so that the \(i\)-th sequence in the first MSA interacts with the \(i\)-th sequence in the second MSA. Therefore, the ground truth permutation is the identity permutation in this case.
We will need to parse the FASTA files and extract species names to group sequences coming from the same species. species_name_func extracts species names from the FASTA headers.
2. Create two pairable multiple sequence alignments (MSAs) and tokenize them
We pick all sequences from 50 species picked uniformly at random from the datasets. This yields two pairable MSAs, each with 581 sequences. Species with only one sequence are removed.
# Organize the MSAs by species ("groupwise")msa_data_species_by_species = [ create_groupwise_seq_records(msa, species_name_func, remove_groups_with_one_seq=True) for msa in msa_data]all_species =list(msa_data_species_by_species[0])assert all_species ==list(msa_data_species_by_species[1])
# Sample a few species to work with, and filter the MSAs to only include these speciesn_species_to_sample =50species = np.random.choice(all_species, n_species_to_sample, replace=False)msa_data_species_by_species = [ {sp: msa_species_by_species[sp] for sp in species}for msa_species_by_species in msa_data_species_by_species]species_sizes = [len(records) for records in msa_data_species_by_species[0].values()]print(f"Species sizes: {species_sizes}")n_seqs =sum(species_sizes)print(f"Number of pairable sequences in this selection: {n_seqs}")
# Bring data back into the original form (list of records)msa_data = [ [record for records_this_species in msa_species_by_species.values() for record in records_this_species]for msa_species_by_species in msa_data_species_by_species]x = one_hot_encode_msa(msa_data[0], device=DEVICE)y = one_hot_encode_msa(msa_data[1], device=DEVICE)
3. Optimize pairings by maximising mutual information between chains: InformationAlignment
from diffpass.train import InformationPairing# Optimization parameters for DiffPaSS bootstrapbootstrap_cfg = {"n_start": 1,"n_end": None,"step_size": 1, # Increase to speed up if needed"show_pbar": True,"single_fit_cfg": None# Default}
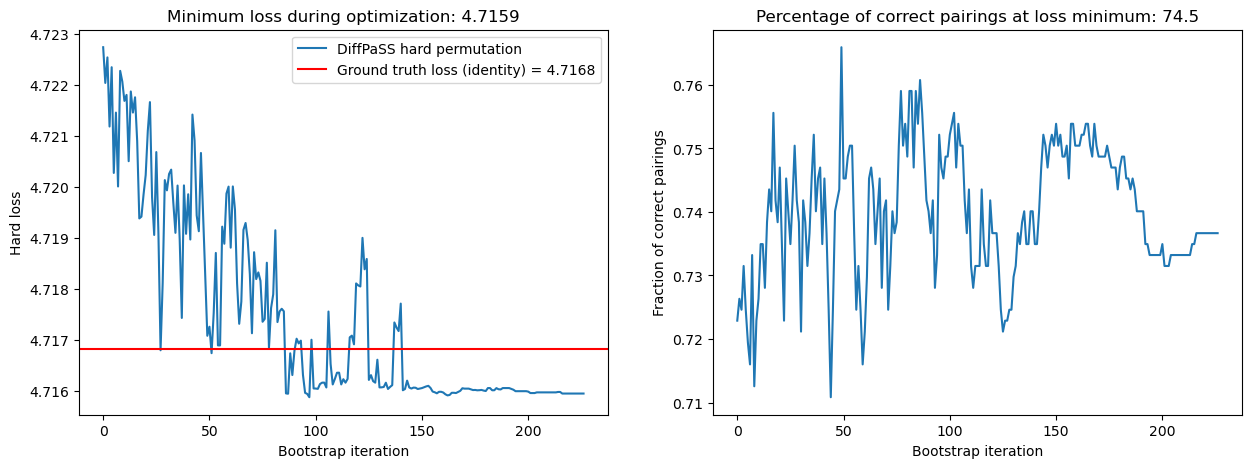
information_pairing = InformationPairing(group_sizes=species_sizes).to(DEVICE)bootstrap_results = information_pairing.fit_bootstrap(x, y, **bootstrap_cfg)
4. Using robustly predicted pairs to bootstrap again! Iterative Pairing Algorithm (IPA)
from diffpass.ipa_utils import get_robust_pairsrobust_pairs = get_robust_pairs( bootstrap_results, cutoff=1.# Decrease to consider more pairs as robust)def print_robust_pairs_stats(robust_pairs): n_robust_pairs =sum(len(robust_pairs_this_species) for robust_pairs_this_species in robust_pairs) frac_pairs_robust = n_robust_pairs / n_seqsprint(f"Percentage of all predicted pairs that are robust: {frac_pairs_robust *100:.1f}%", flush=True) frac_robust_pairs_correct =sum( [pair[0] == pair[1] for robust_pairs_this_species in robust_pairs for pair in robust_pairs_this_species] ) / n_robust_pairsprint(f"Percentage of robust pairs that are correct pairs: {frac_robust_pairs_correct *100:.1f}%", flush=True)
print_robust_pairs_stats(robust_pairs)
Percentage of all predicted pairs that are robust: 9.6%
Percentage of robust pairs that are correct pairs: 100.0%
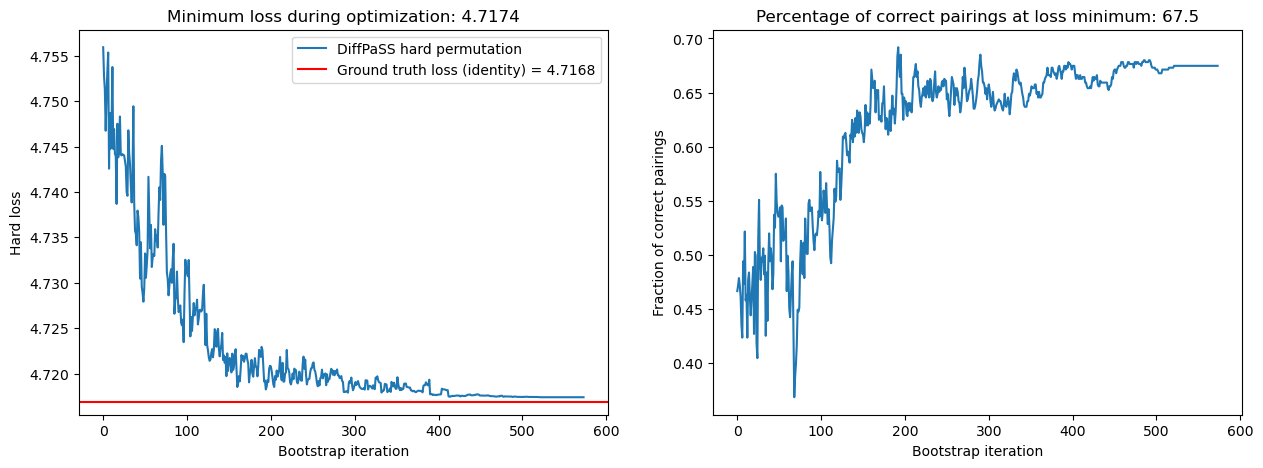
Every robust pair is correct! We can exploit this to start another DiffPaSS bootstrap with these pairs as fixed pairings. And then repeat the process to obtain more robust pairs, and so on. Let’s run this process 4 times, so that we will have run 5 DiffPaSS optimizations in total.
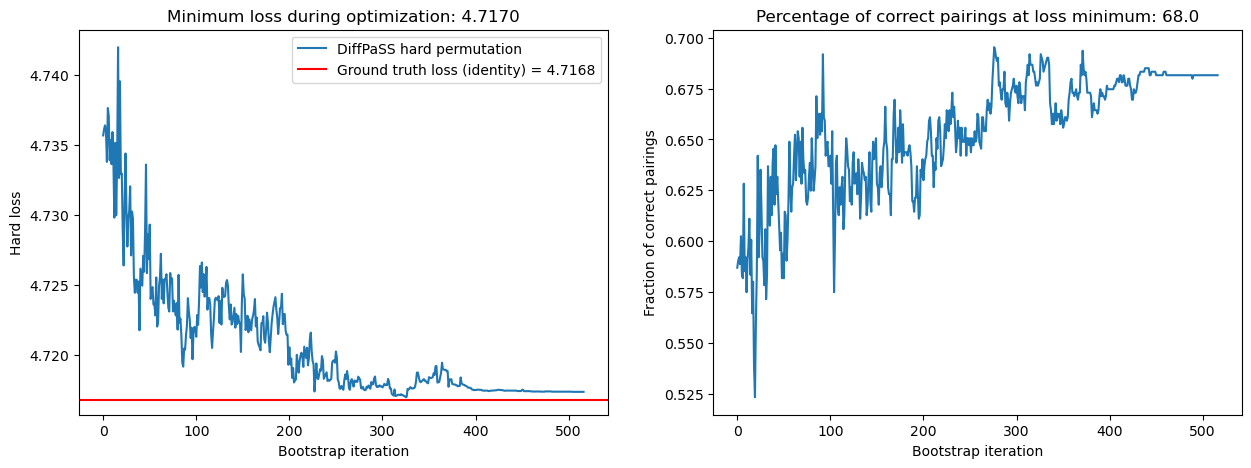
DiffPaSS-IPA: run 2
Percentage of all predicted pairs that are robust: 33.0%
Percentage of robust pairs that are correct pairs: 100.0%
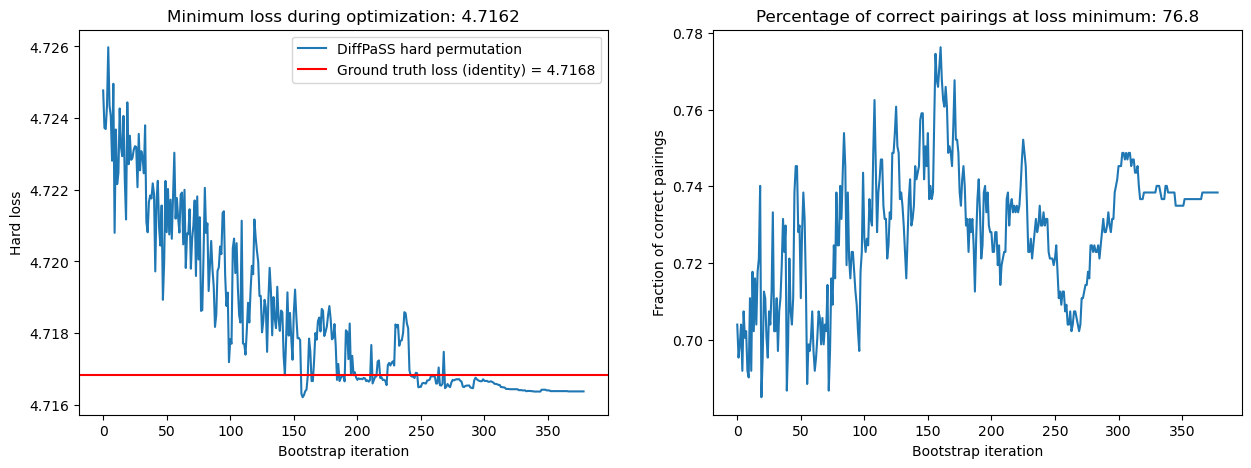
DiffPaSS-IPA: run 3
Percentage of all predicted pairs that are robust: 52.7%
Percentage of robust pairs that are correct pairs: 99.3%
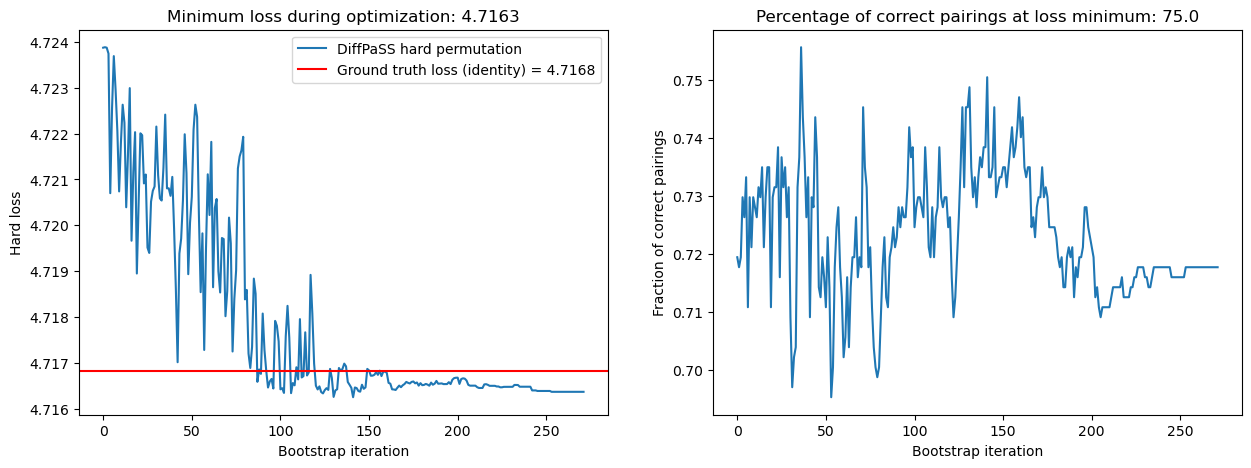
DiffPaSS-IPA: run 4
Percentage of all predicted pairs that are robust: 60.1%
Percentage of robust pairs that are correct pairs: 98.0%
DiffPaSS-IPA: run 5
Percentage of all predicted pairs that are robust: 65.2%
Percentage of robust pairs that are correct pairs: 94.2%
By running DiffPaSS-IPA a total of 5 times, we have obtained a large set of robust pairs (65.2% of all possible pairs!), 94.2% of which are correct.
We have also decreased the hard losses and simultaneously increased the overall percentage of correct pairs, from 68.0% at the first IPA step to 74.5% at the last.
The lowest hard losses obtained by DiffPaSS-IPA for this dataset and these choices of random seeds are actually slightly lower than the ground truth hard loss, which suggests that the optimization has converged to a good solution.